Reverse-Engineering Apple Dictionary
For a while now I have wanted to write a simple dictionary app for the Apple
Watch. The goal was to be able to quickly look up words from paper books,
by storing the book on the watch to be able to do fuzzy matches against the text.
While Apple ships amazing dictionaries with macOS and iOS, they only provide a very
limited API.
On iOS, all you get is
a view into the dictionary via UIReferenceLibraryViewController,
for the Watch, there is no API at all,
and on OS X you get an antique DCSCopyTextDefinition that only
returns a plain-text definition, which is not nice to display. The whole
definition is returned as one blob of non-rich text, no newlines.
It was while attempting to parse this output that I realized it would be so much easier to get the source, which I’m showing here how to do. I open-sourced the code to parse the dictionary on github.
Here is a pic of the OS X dictionary:
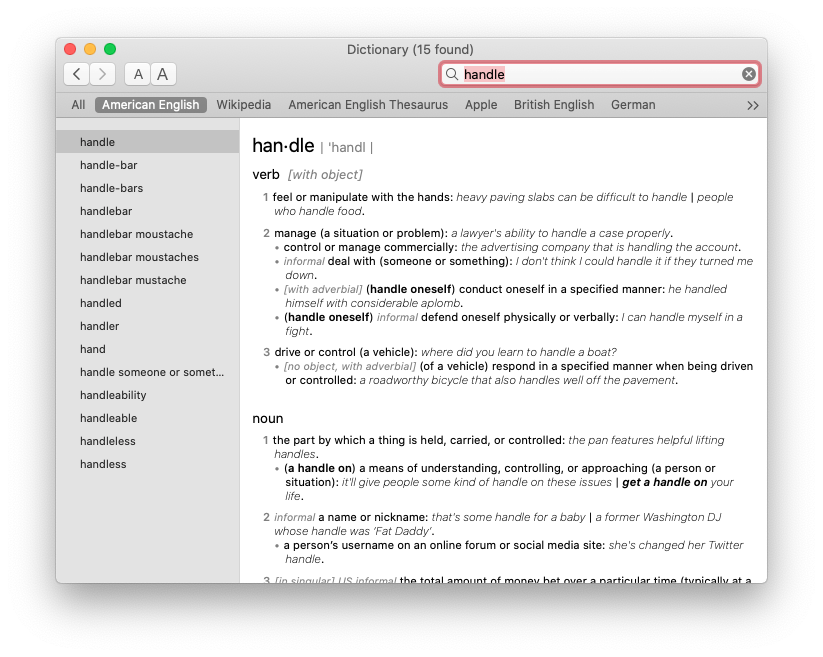
And here is what I managed to extract:

I started by trying to figure out where dictionaries are stored.
Some googling revealed
that they are burried in /System
(at least for macOS 10.15 and possibly higher), at
/System/Library/AssetsV2/
com_apple_MobileAsset_DictionaryServices_dictionaryOSX/
This folder contains various cryptically-named folders ending in .asset,
which represent the different installed dictionaries. E.g., for me:
$ ls
24effbf40402f823bb9d9f6f12b75af3e679a4a6.asset
26e585a43423edb02b25fa7ba9af3fdc08eed6d7.asset
4094df88727a054b658681dfb74f23702d3c985e.asset
96d637557afb292134db05d7d7f30c0fed9cef9f.asset
976258f0b1fad70dd8e7ee7c1b4be8f8536e19a7.asset
a1d5710e8c3932361413f22ff588a1a3c7c337bf.asset
com_apple_MobileAsset_DictionaryServices_dictionaryOSX.xml
Of these, 4094df88727a054b658681dfb74f23702d3c985e.asset is the
“New Oxford American Dictionary”. Going into that folder and
a few levels deeper, we land at a promisingly named “Resources” folder:
$ ls /System/Library/AssetsV2/
com_apple_MobileAsset_DictionaryServices_dictionaryOSX/
4094df88727a054b658681dfb74f23702d3c985e.asset/
AssetData/
New Oxford American Dictionary.dictionary/
Contents/
Resources/
Body.data ca.lproj ms.lproj
DefaultStyle.css cs.lproj no.lproj
Dutch.lproj da.lproj pl.lproj
English.lproj el.lproj pt.lproj
EntryID.data en_AU.lproj pt_PT.lproj
EntryID.index en_GB.lproj ro.lproj
French.lproj es_419.lproj ru.lproj
German.lproj fbm.css sk.lproj
Images fi.lproj sv.lproj
Italian.lproj fr_CA.lproj th.lproj
Japanese.lproj he.lproj tr.lproj
KeyText.data hi.lproj uk.lproj
KeyText.index hr.lproj vi.lproj
NOAD.xsl hu.lproj zh_CN.lproj
Spanish.lproj id.lproj zh_HK.lproj
ar.lproj ko.lproj zh_TW.lproj
which is filled with a whole bunch of files. Sorting by size, it turns out
that Body.data could be a promising candidate at 23MB.
Sadly, it seems to be a binary blob without a discernible content.
$ xxd Body.data | head -n15
00000000: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000040: f74d 7001 0000 0000 ffff ffff 2000 0000 .Mp......... ...
00000050: 0000 0000 da02 0000 ffff ffff ffff ffff ................
00000060: 9480 0000 9080 0000 443b 0400 78da ecbd ........D;..x...
00000070: 6b8c 2457 961e 26ed 6ab5 6fc9 300c c382 k.$W..&.j.o.0...
00000080: 21e3 aac7 10ab b455 3df9 7eb0 67da aa6e !......U=.~.g..n
00000090: 72d8 3d7c 0cc5 2667 b05a 8c1b 3723 6e66 r.=|..&g.Z..7#nf
000000a0: 5c56 44dc e4bd 1155 9dc4 1a18 6261 9918 \VD....U....ba..
000000b0: 717f 505c db4b 2cb4 c66a e911 966b 4382 q.P\.K,..j...kC.
000000c0: b570 0bd6 2f75 f71a ae69 0c2c ff31 6003 .p../u...i.,.1`.
000000d0: b6e1 010c 0102 2c03 fee3 1f86 1fe7 dc1b ......,.........
000000e0: 9195 8f88 cc8c c81b 9955 2407 c3ae aacc .........U$.....
Scanning through the file with xxd, I did not find any visible structure.
However, given that the file is only ~23MB, I was thinking it may just be a ZIP file in disguise.
unzip Body.data
Archive: Body.data
End-of-central-directory signature not found. Either this file is not
a zipfile, or it constitutes one disk of a multi-part archive. In the
latter case the central directory and zipfile comment will be found on
the last disk(s) of this archive.
unzip: cannot find zipfile directory in one of Body.data or
Body.data.zip, and cannot find Body.data.ZIP, period.
No luck! Same for tar xvf.
At this moment, I remembered that the last time I had been thinking about this problem, years ago, I had stumpled upon some cryptic C code. I remembered fiddling around with XML, so I tried to dig up old projects, but sadly, I must have deleted them.
Some googling later, I stumpled upon the very gist
I had found years ago. It’s a very short and sweet python script to
extract entries from Data.entry. However, it’s also somewhat magical
in that it’s not documented, seeks random offsets, and even makes use
of the struct library.
But, it also does import zlib, so I thought, let’s try
to reverse engineer it myself.
The first simple thing to try was to just attempt to find a ZIP file by going through the bytes of the file one by one. After all, it was very plausible that the file starts with some Apple header followed by some compressed data.
import zlib
import itertools
DATA_FILE_PATH = ...
with open(DATA_FILE_PATH, 'rb') as f:
content_bytes = f.read()
# Try all offsets to see if we find a ZIP file
for offset in itertools.count():
print(f'Trying {offset}...')
try:
content_decompressed = zlib.decompress(content_bytes[offset:])
print('Found ZIP!')
break
except zlib.error: # Current content_bytes is not a zipfile -> skip a byte.
pass
… and, low and behold, at byte number 108, a ZIP file starts!
Trying 102...
Trying 103...
Trying 104...
Trying 105...
Trying 106...
Trying 107...
Trying 108...
Found ZIP!
Very exciting! What’s in this ZIP?
>>> content_decompressed.decode()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
Ok, so already the first byte cannot be decoded by ‘utf-8’, that’s a bit sad.
>>> print(content_decompressed[:20])
b'\xa3\x02\x00\x00<d:entry xmlns:d'
Aha, already a few bytes later, some XML starts. For now, let’s just ignore the first four bytes.
>>> content_decompressed[4:].decode()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe7 in position 2065: invalid continuation byte
That’s already more promising, we can decode 2065 bytes. Looking around position 2065, we find:
>>> print(content_decompressed[2055:2085])
b'an></d:entry>\n\xe7\x02\x00\x00<d:entry xml'
# ^ | |
# newline |__ 4 bytes ___|
We see the entry ends, followed by a newline \n, some more
seemingly random bytes, and another entry starts!
For reference, here is the first entry (defining 007, as it turns out):
<d:entry xmlns:d="http://www.apple.com/DTDs/DictionaryService-1.0.rng"
id="m_en_gbus1179660"
d:title="007"
class="entry">
<span class="hg x_xh0">
<span role="text" class="hw">007 </span>
</span>
<span class="sg">
<span id="m_en_gbus1179660.005" class="se1 x_xd0">
<span role="text" class="posg x_xdh">
<span d:pos="1" class="pos">
<span class="gp tg_pos">noun </span>
<d:pos/>
</span>
</span>
<span id="m_en_gbus1179660.006" class="msDict x_xd1 t_core">
<span d:def="1" role="text" class="df">
the fictional British secret agent James Bond, or someone based on,
inspired by, or reminiscent of him<span class="gp tg_df">.</span>
<d:def/>
</span>
</span>
</span>
</span>
</d:entry>
Exploring some more, I did not find a pattern in these delimiter bytes except it always being 4 bytes. I’m assuming they somehow tell you how long the next entry is. But we can just always ignore the 4 bytes and keep reading until the next newline appears.
def split(input_bytes):
# The first four bytes are always not UTF-8.
input_bytes = input_bytes[4:]
entries = []
while True:
# Find the next newline, which delimits the current entry.
try:
next_offset = input_bytes.index('\n'.encode('utf-8'))
except ValueError: # No more new-lines -> no more entries!
break
entry_text = input_bytes[:next_offset].decode('utf-8')
entries.append(entry_text)
# There is always 4 bytes of chibberish between entries. Skip them
# and the new lines (for a total of 5 bytes).
input_bytes = input_bytes[next_offset + 5:]
return entries
Aaaand… that yielded a measly 152 entries. Very sad. Where is the rest? Let’s first see what entries we have:
007, 2.0, 404, 420, 4D printing, 4K, 911, 999, a, a, A, A, a-, a-, a-, a-, -a,
-a, -a, A1, A3, A4, A5, aa, AA, AAA, AAAS, Aachen, AAD, Aadhaar, Aalborg, Aalto,
Alvar, AAM, A & M, A & R, aardvark, aardwolf, aargh, Aarhus, Aaron, Aaron, Hank,
Aaron's beard, Aaron's rod, AARP, AAU, AAUP, AAVE, abs, Ab, Ab, AB, AB, ab-, ABA,
abaca, aback, abacus, Abadan, Abaddon, abaft, Abakan, abalone, abandon, abandoned,
abandonment, abandonware, abase, abasement, abash, abashed, abate, abatement,
abattoir, a battuta, abaxial, abaya, Abba, Abba, abbacy, Abbas, Ferhat, Abbas,
Mahmoud, Abbasid, abbatial, abbé, abbess, Abbevillian, abbey, Abbey Road,
abbot, Abbott, Berenice, Abbott, Sir John, Abbott, Tony, abbr., abbreviate,
abbreviated, abbreviation, ABC, ABC, ABC, ABC Islands, ABD, abdicate,
abdication, abdomen, abdominal, abdominoplasty, abdominous, abducens, abducens
nerve, abduct, abductee, abduction, abductor, Abdul Hamid II, Abdul-Jabbar,
Kareem, Abdullah ibn Hussein, Abdullah II, Abdul Rahman, Tunku, Abe, Shinzo,
abeam, abecedarian, abed, abeer, Abel, Abel, Niels Henrik, Abelard, Peter,
abele, abelian, Abenomics, Abeokuta, Aberdeen, Aberdeen Angus, Aberdonian,
Abernathy, Ralph David, aberrant, aberration, Abertawe, abet, abettor,
abeyance, abhor, abhorrence, abhorrent, abide, abiding, Abidjan, Abilene,
ability, -ability, Abington, ab initio, abiogenesis
Clearly, we are doing something right, but we are just getting the very first entries.
Going back to the first part, I realized that content_decompressed
is actually very short compared to all available bytes: Decompressing yielded
277kB of data, while the whole Body.data file is 24MB.
So, probably there more ZIP files. If so, how do we find them?
Obviously, we cannot just skip 277kB and try searching again,
as the compressed ZIP is smaller than 277kB. And blindly trying to do
zlib.decompress at each possible offset takes forever (and is inelegant).
However, reading the the zlib documentation, it turns out that there
is also a slightly fancier API. We can get a “Decompress” instance using
zlib.decompressobj(), call decompress() on that, and the instance
will actually return unused_data. (Very cool!)
with open(DATA_FILE_PATH, 'rb') as f:
content_bytes = f.read()
while True:
try:
decompressobj = zlib.decompressobj()
content_decompressed = decompressobj.decompress(content_bytes)
entries = split(content_decompressed)
# In the next loop step, we use the unused data to look for a ZIP file.
content_bytes = decompressobj.unused_data
except zlib.error: # Current content_bytes is not a zipfile -> skip a byte.
print('Error, skipping a byte...')
content_bytes = content_bytes[1:]
And this works. Turns out there is only 12 bytes after the first ZIP file before the next one starts, and then this pattern repeats for the rest of the file.
That’s (almost) all we need to parse the whole Body.data.
The only (minor) problem
was that the file ends with a bunch of meta information about the dictionary,
which triggered some asserts in my code. But overall, with this, I was able
to extract definitions for 103013 words! Putting them all in a python dict
and pickle-ing this dict yields an impressive 200MB file. Zipping that file
yields again a ~24MB file.
What do we do with this? Well, it’s XML, which seems to be made mostly of HTML tags.
In the Resources folder, there is also DefaultStyle.css. Indeed,
wrapping the XML in some HTML boiler plate, including the style, and opening
the resulting file in Chrome yielded the following nice view:
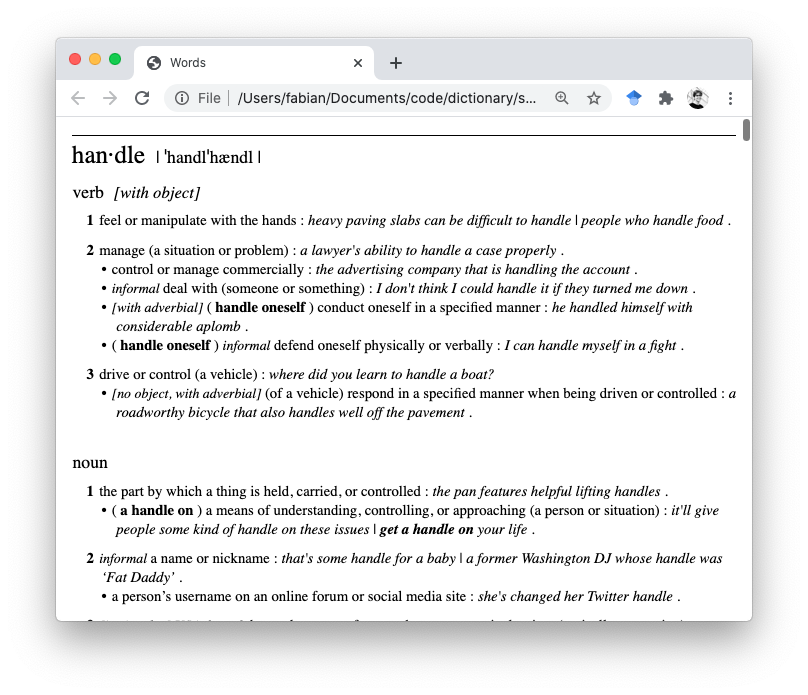
Parsing some of the XML
To actually use the parsed XML in a dictionary app for books, some further preprocessing has to be done, to turn the input text into a list of definitions that are actually found in the dictionary.
As a first step, I want to tokenize the text, i.e., split the text into words.
For example, I want to turn
"Nice doors", he said into an array [Nice, door, he, said]. For this,
I used the Python Natural Language Toolkit, nltk,
in particular it’s word_toeknize function:
>>> from nltk import tokenize
>>> text = '"Nice door", he said.'
>>> tokenize.word_tokenize(text)
['``', 'Nice', 'door', '"', ',', 'he', 'said']
It appeared that this does keep some punctuation in the words, so I did some manual postprocessing:
words = tokenize.word_tokenize(text)
# Remove punctuation in tokens, as ntlk tokenizes for example "they'll" as
# [they, 'll]. The resulting "ll" will be ditched in a later stage.
# Also removes tokens that are just quotes, which turn into empty tokens,
# removed at the MIN_WORD_LEN stage below.
words = (w.strip("'.-`\"") for w in words)
# Ditches some genitives and third person singulars. In Python 3.9 this
# should be `removesuffix` but the `replace` works well enough in this context.
words = (w.replace("'s", '') for w in words)
# Removes abbreviations such as "e.g."
words = (w for w in words if '.' not in w)
# Removes most punctuation from the list, such as ",", ":", etc.,
# also removes empty tokens.
MIN_WORD_LEN = 1
words = (w for w in words if len(w) > MIN_WORD_LEN)
# Removes all numbers
words = (w for w in words if w and not all(c.isdigit() for c in w))
The resulting list of words was then lemmatized with WordNetLeammanizer,
which turns, for example, houses into house. The lemmanizer
requires the caller to specify whether the word is an adjective, adverb, verb
or noun. Depending on this type, a word might be lemmanized differently.
I decided to just try all types for all words, and keep the lemmanized forms
if they are in the dictionary:
# First turn our list of words into a dictionary mapping words to how
# often they appear.
word_counts = collections.Counter(words)
word_dict = ... # New Oxford American Dictionary as parsed above.
lemma = WordNetLemmatizer()
word_counts_lemmad = collections.defaultdict(int)
for w, count in word_counts.items():
# The possible lemmanized forms of the word `w`.
possible_words = set()
for t in wordnet.POS_LIST: # where POS_LIST == [ADJ, ADV, VERB, NOUN]
w_lemmad = lemma.lemmatize(w, pos=t)
if w_lemmad != w:
possible_words.add(w_lemmad)
if not possible_words: # No lemmanized form found, assume word itself.
possible_words = {w}
for possible_w in possible_words:
if possible_w in word_dict:
word_counts_lemmad[possible_w] += count
I assume that there are better ways to process the text, and nltk seems to have many more powerful functions, but the above code worked reasonably well for my purpose. The full preprocessing code can be found in extract.py.
Exploring the output, I realized a significant number of terms in the
input text was not found in the dictionary.
For example, the noun vitals was not found in the dictionary,
as it hides in the definition of the adjective vital, and vitals is not
lemmatized during preprocessing as the only valid base form is the noun vitals.
Thus, the above pre-processing will skip vitals, as it’s not in the word_dict.
Looking at the entry for the term vital, we see:
vi·tal | ˈvīdl |
adjective
1 absolutely necessary or important; essential : secrecy is of vital importance | it is vital that the system is regularly maintained .
• indispensable to the continuance of life : the vital organs .
2 full of energy; lively : a beautiful, vital girl .
3 archaic fatal : the wound is vital .
noun ( vitals )
the body's important internal organs, especially the gut or the genitalia : he felt the familiar knot contract in his vitals .
• short for vital signs.
In the second definition, we find the term vitals. Looking at the XML,
we see:
<span class="x_xdh">
<span role="text" class="posg">
<span d:pos="2" class="pos">
<span class="gp tg_pos">noun </span>
<d:pos/>
</span>
</span>
<span class="fg">
<span class="gp tg_fg">(</span>
<span class="f">vitals</span> <!-- the desired term! -->
<span class="gp tg_fg">) </span>
</span>
</span>
<span id="m_en_gbus1132680.014" class="msDict x_xd1 t_core">
<span d:def="2" role="text" class="df">the body's important internal organs, especially the gut or the genitalia<d:def/></span>
<span role="text" class="gp tg_df">: </span>
<span role="text" class="eg">
<span class="ex"> he felt the familiar knot contract in his vitals</span>
<span class="gp tg_eg">. </span>
</span>
<span role="text" class="gp tg_msDict"> </span>
</span>
I created the following XPath to locate these terms
XPATH_OTHER_WORDS = '//span[@class="fg"]/span[@class="f"]'
Trying the XPath on all definitions seemed to uncover a lot of additional terms.
Mostly, these are plurals or phrasal verbs (the
definition of act contains act on, act for, etc.),
but this helped find some words in my input text.
On a side note, I learned during this project that Chrome has a really great way to test XPath queries (while writing I realized Safari actually also has this). Right Click -> “Inspect”, CMD+F, note the search bar at the bottom of the window:
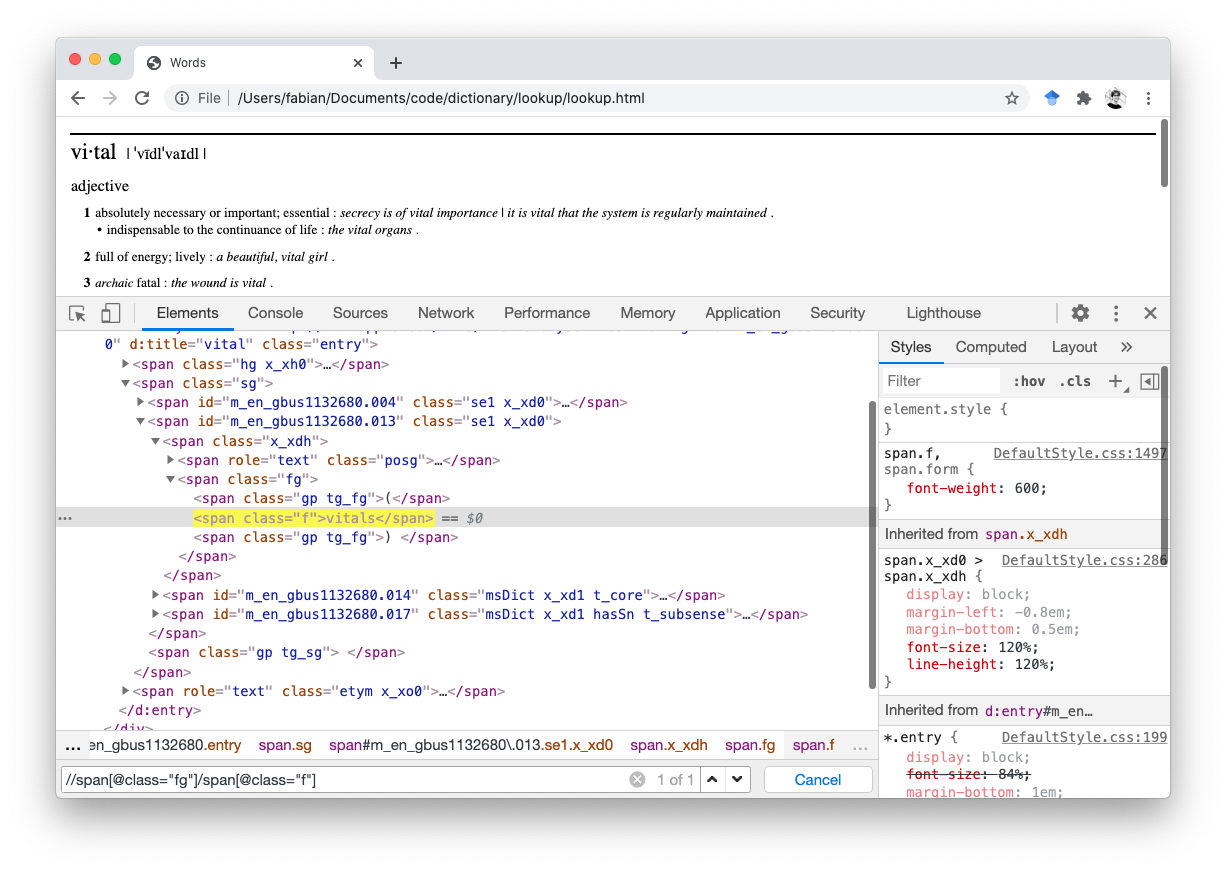
You can even select XML elements and Right Click -> Copy -> XPath to extract a somewhat verbose XPath.
Going back to the definitions, I wrote a second XPath to get derivative definitions. It turns out a lot of terms hide there, in particular adverbs, but also a lot of derived nouns. An example entry with useful derivatives:
snoop | sno͞op | informal
verb [no object]
investigate or look around furtively [...]
noun [in singular]
a furtive investigation [...]
DERIVATIVES
snooper | ˈsno͞opər | noun
snoopy adjective
Overall, this allowed me to find most words in my input text. The remaining terms were mostly names or book-specific jargon.
Getting it onto the Apple Watch
I wanted to look at these entries on the Watch. Sadly, it turns out there
is no UIWebView (used to render HTML in iOS) in WatchKit. But,
NSAttributedString can be constructed from a HTML string. As it turns out,
it can even contain CSS, as long as the CSS is inlined in the HTML as a
<style> element in the header.
let HTML_ENTRY_START = """
<html lang="en">
<head>
<meta charset="utf-8">
<title>Words</title>
<style>
... Full DefaultStyle.css file here ...
</style>
</head>
<body>
"""
let HTML_ENTRY_END = "</body>"
let definition: String = ... // The XML
let htmlDefinition = HTML_ENTRY_START + definition + HTML_ENTRY_END
let data = htmlDefinition.data(using: .utf8)!
let attributedDefinition = try NSAttributedString(
data: data,
options: [.documentType: NSAttributedString.DocumentType.html],
documentAttributes: nil)
outputLabel.setAttributedText(attributedDefinition)
Conclusion
This was a fun little exercise in reverse engineering. I’m not sure I would
have gone through this had I not found the gist and seen import zlib,
as before that, the file looked very daunting. However, seeing that import
statement gave the necessary energy to just push a bit further,
and the rest was mostly a breeze.